Optical Character Recognition (OCR)¶
Introduction¶
Optical Character Recognition (OCR) is a technology that enables the conversion of printed or hand-written text into machine-readable digital text. It is used to extract text from physical documents, such as scanned images, photographs, or PDF files, and convert it into editable and searchable digital text. OCR technology finds applications in various fields, including document digitization, data entry automation, archival systems, text-to-speech conversion, and intelligent character recognition. It significantly reduces manual effort, improves data accessibility, and enables efficient information retrieval from printed or handwritten documents. Actable AI currently uses Tesseract for OCR. The extracted text can then be further processed using the Information Extraction analytic. To user OCR, you need to have an image dataset uploaded on our platform. You must upload a zip file that contains images for extraction (images can be in any nested folders).
Note
A video demonstration using the OCR and information extraction analytics may be viewed here.
Parameters¶
There are two tabs containing options that can be set, namely the Data tab and the OCR tab. The configurable settings are located in the OCR tab, as follows:
Languages: the language(s) of the text within the images (e.g. English).
Model Type: The type of model to choose, with a trade-off between performance and speed:
Fast: The fastest model, but may also yield the worst performance.
Normal: Balanced between performance and computation time.
Best: Model achieving the best performance, but may take a longer time to process images.
Page Segmentation Mode: Guides the model as to how to segment the image, with the following options:
Orientation and Script Detection (OSD) only
Fully automatic page segmentation, but no OSD (default)
Assume a single column of text of variable sizes
Assume a single uniform block of vertically aligned text
Assume a single uniform block of text
Treat the image as a single text line
Treat the image as a single word
Treat the image as a single word in a circle
Treat the image as a single character
Sparse text. Find as much text as possible in no particular order
Sparse text with OSD
Raw line. Treat the image as a single text line, bypassing hacks that are Tesseract-specific.
More information about each of these options can be viewed here.
Furthermore, if any features are related to time, they can also be used for visualization:
Time Column: The time-based feature to be used for visualization. An arbitrary expression which returns a DATETIME column in the table can also be defined, using format codes as defined here.
Time Range: The time range used for visualization, where the time is based on the Time Column. A number of pre-set values are provided, such as Last day, Last week, Last month, etc. Custom time ranges can also be provided. In any case, all relative times are evaluated on the server using the server’s local time, and all tooltips and placeholder times are expressed in UTC. If either of the start time and/or end time is specified, the time-zone can also be set using the ISO 8601 format.
Case Study¶
Note
This example is available in the Actable AI web app and may be viewed here.
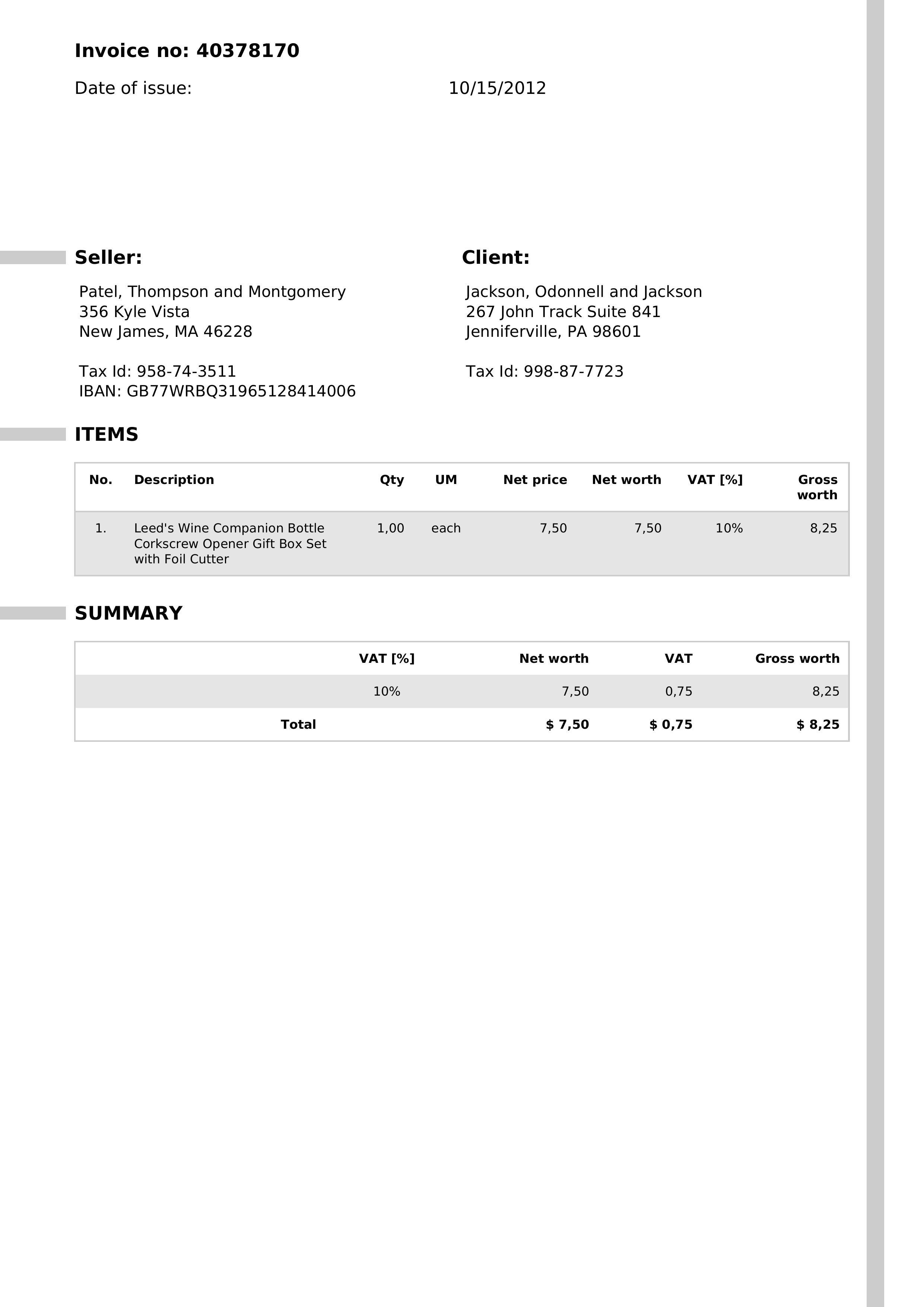
Suppose we have a number of invoices saved as images. Each image contains one invoice written in English, as shown in the below example:
We set our parameters as follows:
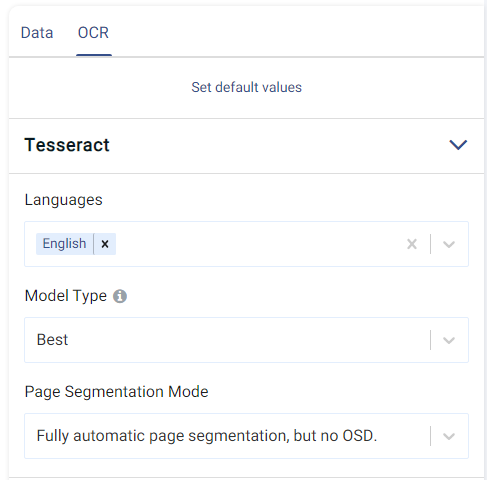
As can be observed, we have set the language to ‘English’, will be using the ‘Best’ model, and will be using the default Page Segmentation Mode.
Running the analytic will recognize the characters in the images provided, and save them as text. The results of the OCR on the provided invoices can be seen below:

The information extraction analytic could then be used to make sense of the extracted text, and retrieve information about the data contained in each invoice. More details may be found in the Information Extraction documentation.