Sentiment Analysis¶
Introduction¶
Sentiment analysis is a Natural Language Processing (NLP) technique that determines the affective state and subjective views of a person. In Actable AI, sentiment analysis is applied to determine the polarity of a given piece of text, namely if the overall sentiment or opinion is positive, negative, or neutral.
Sentiment analysis can be used to help small business owners to analyze customer feedback, monitor business performance, and better understand customer needs.
Actable AI provides word cloud and sentiment category results for provided texts. More information is given hereunder.
Parameters¶
There are two tabs containing options that can be set: the Data tab, and the Customize tab, as follows:
Data tab:
Text: The column in the dataset containing text from which keywords and their sentiments are to be extracted.
Minimum Frequency: The minimum number of occurrences of a word to be displayed in the word cloud. The value should be greater than 0. Changing this control takes effect instantly in the result panel.
Filters (optional): Set conditions on columns (features), in order to remove any samples in the original dataset which are not required. If selected, only a subset of the original data is used in the analytics.
Furthermore, if any features are related to time, they can also be used for visualization:
Time Column: The time-based feature to be used for visualization. An arbitrary expression which returns a DATETIME column in the table can also be defined, using format codes as defined here.
Time Range: The time range used for visualization, where the time is based on the Time Column. A number of pre-set values are provided, such as Last day, Last week, Last month, etc. Custom time ranges can also be provided. In any case, all relative times are evaluated on the server using the server’s local time, and all tooltips and placeholder times are expressed in UTC. If either of the start time and/or end time is specified, the time-zone can also be set using the ISO 8601 format.
Customize tab:
The customize panel can be used to customize the appearance of the word cloud. All of the following parameters take effect instantly after being changed:
Minimum Font Size: Font size for the smallest value in the list.
Maximum Font Size: Font size for the biggest value in the list.
Word Rotation: Rotation to apply to words in the cloud.
Linear Color Scheme: Color scheme of the word cloud.
Case Study¶
Note
This example is available in the Actable AI web app and may be viewed here.
Suppose we would like to analyze the latest news related to the economy. A sample of the data is as follows:
TEXT |
|---|
NEW YORK – Yields on most certificates of deposit offered by major banks dropped more than a tenth of a percentage point in the latest week, reflecting the overall decline in short-term interest rates.</br></br>On small-denomination, or “consumer,” CDs sold directly by banks, the average yield on six-month deposits fell to 5.49% from 5.62% in the week ended yesterday, according to an 18-bank survey by Banxquote Money Markets, a Wilmington, Del., information service.</br></br>On three-month “consumer” deposits, the average yield sank to 5.29% from 5.42% the week before, according to Banxquote. Two banks in the Banxquote survey, Citibank in New York and CoreStates in Pennsylvania, are paying less than 5% on threemonth small-denomination CDs.</br></br>Declines were somewhat smaller on five-year consumer CDs, which eased to 7.37% from 7.45%, Banxquote said.</br></br>Yields on three-month and six-month Treasury bills sold at Monday’s auction plummeted more than a fifth of a percentage point from the previous week, to 5.46% and 5.63%, respectively. |
The Wall Street Journal Online</br></br>The Morning Brief, a look at the day’s biggest news, is emailed to subscribers by 7 a.m. every business day. Sign up for the e-mail here.</br></br>On Friday evening, with Congress out of town on its summer recess and Americans heading into a mid-August weekend, the Bush administration sent a message to the states: The federal government will make it tougher for a national children’s insurance program to cover the offspring of middle-income families.</br></br>The State Children’s Health Insurance Program was created in 1997 to help children whose families couldn’t afford insurance but didn’t qualify for Medicaid, and administration officials tell the New York Times that the changes are aimed at returning the program to its low- income focus and assuring it didn’t become a replacement for private insurance. Administration point man Dennis Smith wrote to state officials saying there would be new restrictions on the District of Columbia and the 18 states – including California and New York – that extend or plan to extend coverage for children whose families make more than 250% of Federal poverty levels. For a family of three that 250% is $42,900, and for a family of four it’s $51,625. Under the new limits, a child from a family making more would have to spend one year uninsured before qualifying, and any state that wants to extend coverage would have to assure Washington that at least 95% of children eligible for SCHIP or Medicaid are enrolled in one of the programs. But as the Associated Press reports, no state can currently make such assurances.</br></br>Rachel Klein, deputy director of health policy for advocacy group Families USA, tells the AP that since many families above the 250% threshold can’t afford private insurance, “the effect of this policy is to have more uninsured kids.” Ann Clemency Kohler, deputy commissioner of human services in New Jersey, tells the Times the changes “will cause havoc with our program and could jeopardize coverage for thousands of children.” States have already been imposing waiting periods and taking other steps to prevent parents from moving their children from private insurance to SCHIP, which currently serves some 6.6 million children, the Washington Post notes. The administration’s new restrictions come as the program, which expires at the end of next month if Congress doesn’t reauthorize it, is the subject of a larger political fight that pits the White House against Democrats and some Republicans in Congress and state capitals. |
WASHINGTON – In an effort to achieve banking reform, Senate negotiators and the Bush administration have agreed to drop efforts to allow banks to expand further into the securities business.</br></br>The compromise is one of several the Senate Banking Committee is pursuing to remove obstacles its banking bill will face when the Senate starts voting on the measure, perhaps today. The latest version of the House banking bill also drops the administration’s proposals to broaden bank entry into the securities business.</br></br>Last night, the House began its second attempt to pass a banking bill after failing last week, in part because of disagreement over how to allow banks into the securities business. The House adopted on a voice vote provisions that would replenish the bank deposit insurance fund, tighten bank regulation, trim the scope of deposit insurance, and restrict the Federal Reserve Board’s ability to keep sick banks alive with loans.</br></br>But the House delayed until today a vote on an amendment to allow banks to branch nationwide and on final passage of the banking bill to give the House leadership and the administration more time to drum up support for the bill.</br></br>House Speaker Thomas Foley (D., Wash.) is working hard to win passage of the bill in the face of significant opposition from Rep. John Dingell (D., Mich.), who believes the bill should include provisions imposing stiffer regulation on banks in the securities business. |
The statistics on the enormous costs of employee drug abuse are well known (at least $70 billion per year, according to December 1985 testimony before the House Labor Subcommittee on Health and Safety). Management is under pressure to reduce productivity losses, turnover, insurance costs and the risk of lawsuits for personal and property damage caused by drug-impaired workers. Management also is under sales pressure from a growing cadre of laboratories, test-kit manufacturers and consultants who extol the virtues of testing. A common argument is the following: “Your competitors are starting to require drug tests. If you don’t, their work force will be clean and you will end up with all the junkies.”</br></br>Many companies that have implemented widespread drug-testing programs, however, have learned that there is a downside to testing. They have experienced the protests of employees and civil libertarians and have watched the proliferation of lawsuits alleging invasion of privacy, defamation and other legal theories. A Texas railroad employee was awarded $200,000 in damages when his employer misreported the results of a drug test. Numerous other cases are pending.</br></br>Is there a middle ground? Can safety and efficiency be protected without invading the privacy of applicants and employees?</br></br>A growing number of companies have concluded that drug testing should be the least important part of a comprehensive drug-abuse program. The starting point is a drug-awareness program to educate managers, supervisors and employees about the dangers and signs of drug abuse. The second part of the program is an effective employee-assistance program (EAP). Rehabilitation is preferable to punishment or dismissal (at least for initial or nonserious offenses) because it encourages employees to seek help voluntarily, improves labor relations and is cost-effective by restoring valuable employees to productive status. More than one company that heedlessly adopted a “screen and fire” policy on drugs had second thoughts after discovering traces of drugs in some of their most productive employees.</br></br>There may be a place for drug testing in a company’s drug-abuse program, but there are limits to the effectiveness of testing. To begin with, the accuracy of some drug tests varies widely, and the test results are often unacceptable even when performed by professional laboratories. Last year the Centers for Disease Control published the results of a 10-year study of laboratory testing for amphetamines, barbiturates, cocaine, codeine, methadone and morphine. Virtually all of the laboratories in the study had unacceptably high error rates. |
NEW YORK – Indecision marked the dollar’s tone, as traders paused for breath, awaiting a critical monthly U.S. employment report for release today.</br></br>The dollar ended the New York day slightly weaker against both the euro and the yen.</br></br>Market participants were also reluctant to make major bets on the yen, following a stream of more rigorous-sounding statements from top Japanese officials about the issue of bank reforms.</br></br>Late yesterday afternoon in New York, the euro was at 98.77 cents, slightly stronger than its 98.68-cent level late Wednesday. Against the yen, the dollar was trading at 122.59 yen, down modestly from 122.84 yen. Against the Swiss franc, the dollar was at 1.4782 francs, unchanged, while sterling was changing hands at $1.5698, up from $1.5689.</br></br>The euro managed to raise its head briefly above 99 cents during New York trade, for the first time in roughly four weeks, taking advantage of some softness in stock markets and some worries about the state of the U.S. economic recovery ahead of the employment report. |
The parameters are set as follows:
Review Result¶
The result view contains the Word Cloud, Sentiment, mentions, Context, and Table tabs, as follows:
Word Cloud¶
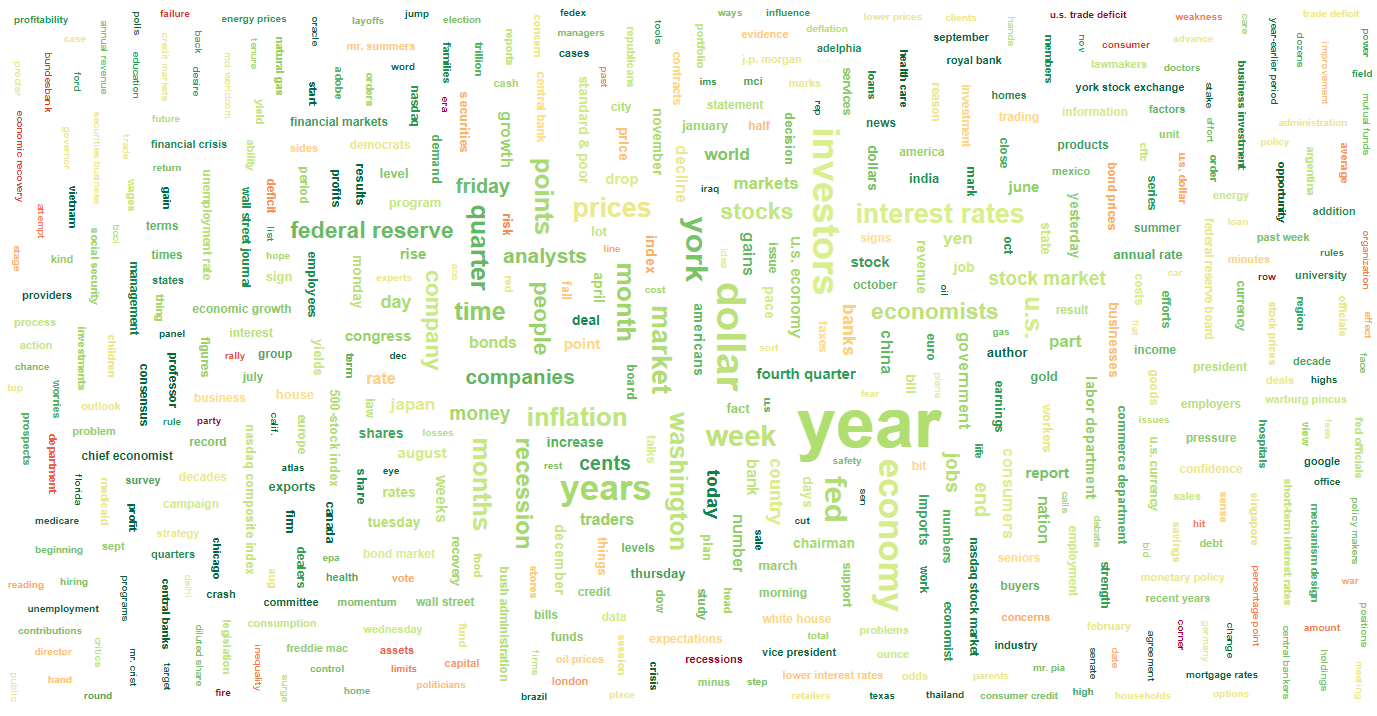
The Word Cloud visualizes the most important textual data points. In general, the higher the occurrence of a specific word in the source of textual data, the bigger and bolder the appearance of the word in the word cloud.
In our example, the word cloud obtained from the economy news data can be seen below. It can be observed that the most frequently-occurring words include year, dollar, and investors.
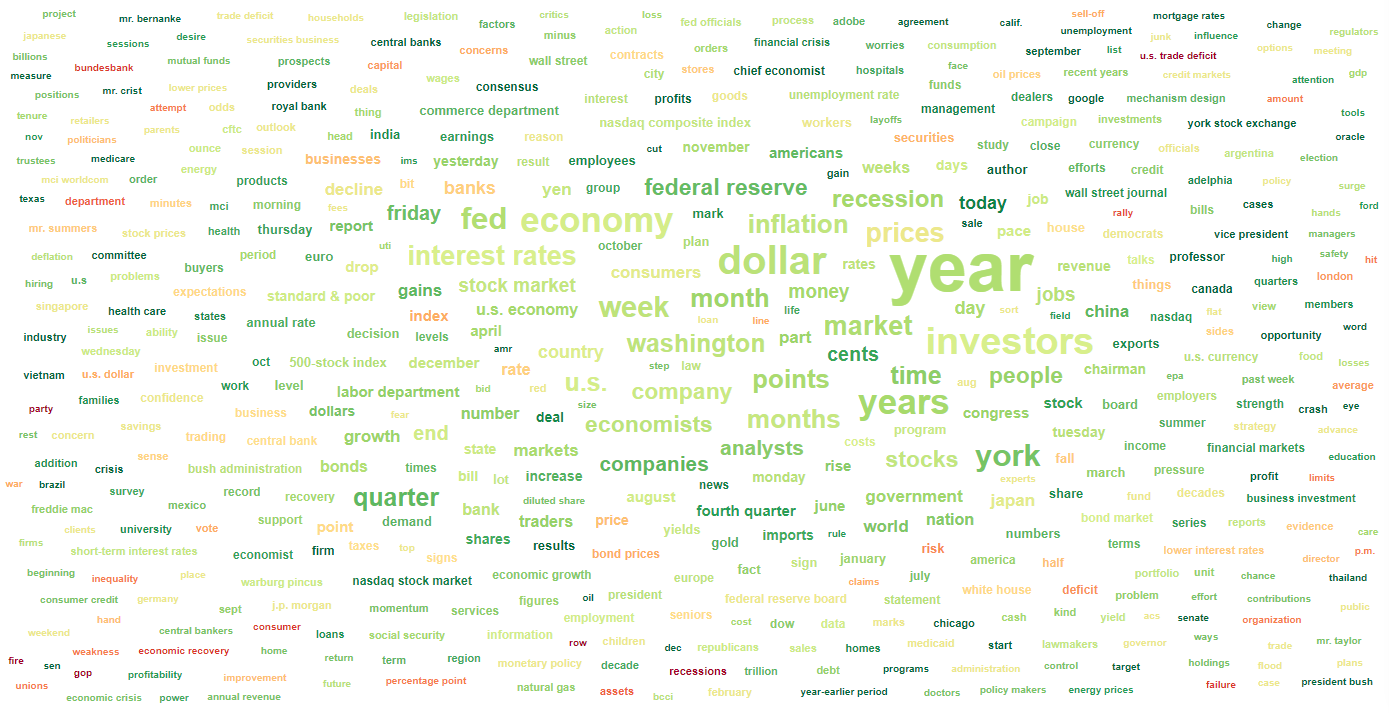
As previously mentioned, the appearance can be customized by Minimum Frequency and the options under Customize to adjust the font size, rotation and color scheme. For instance, changing the Word Rotation setting from square to flat yields the following word cloud:
Sentiment¶
The number of occurrences that a word is classified as being negative and positive are represented in a diverging bar chart. Hovering the mouse cursor on the bars reveals the exact values. An example of which can be seen in the following image:
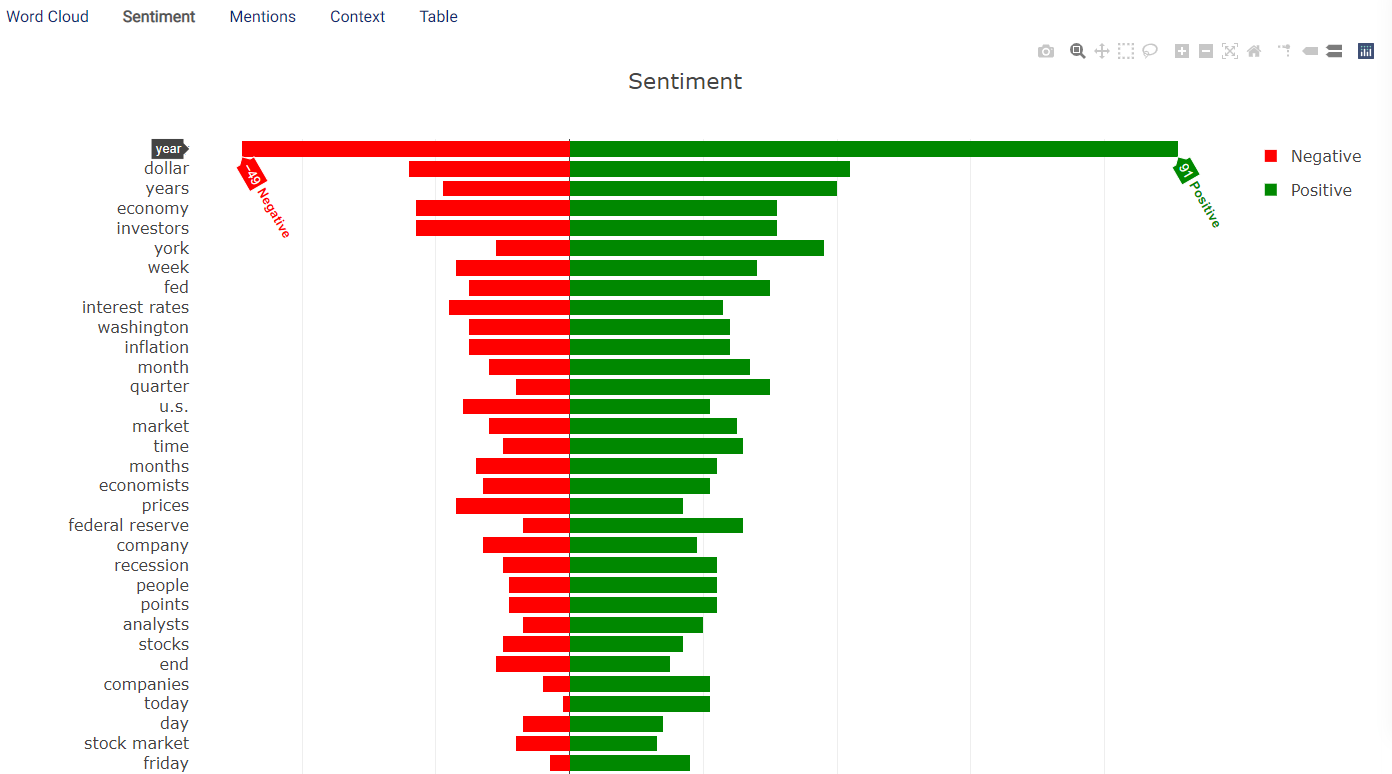
In this case, it can be observed that year was mentioned 49 times in a negative context, while the overall sentiment of 91 occurrences was positive.
Mentions¶
The total number of mentions of each word in the dataset is represented in a bar chart, ordered in descending order (with the most frequently-occurring word at the top, followed by the second most frequently-occurring word, and so on). Hovering the mouse cursor on a bar displays the exact value:
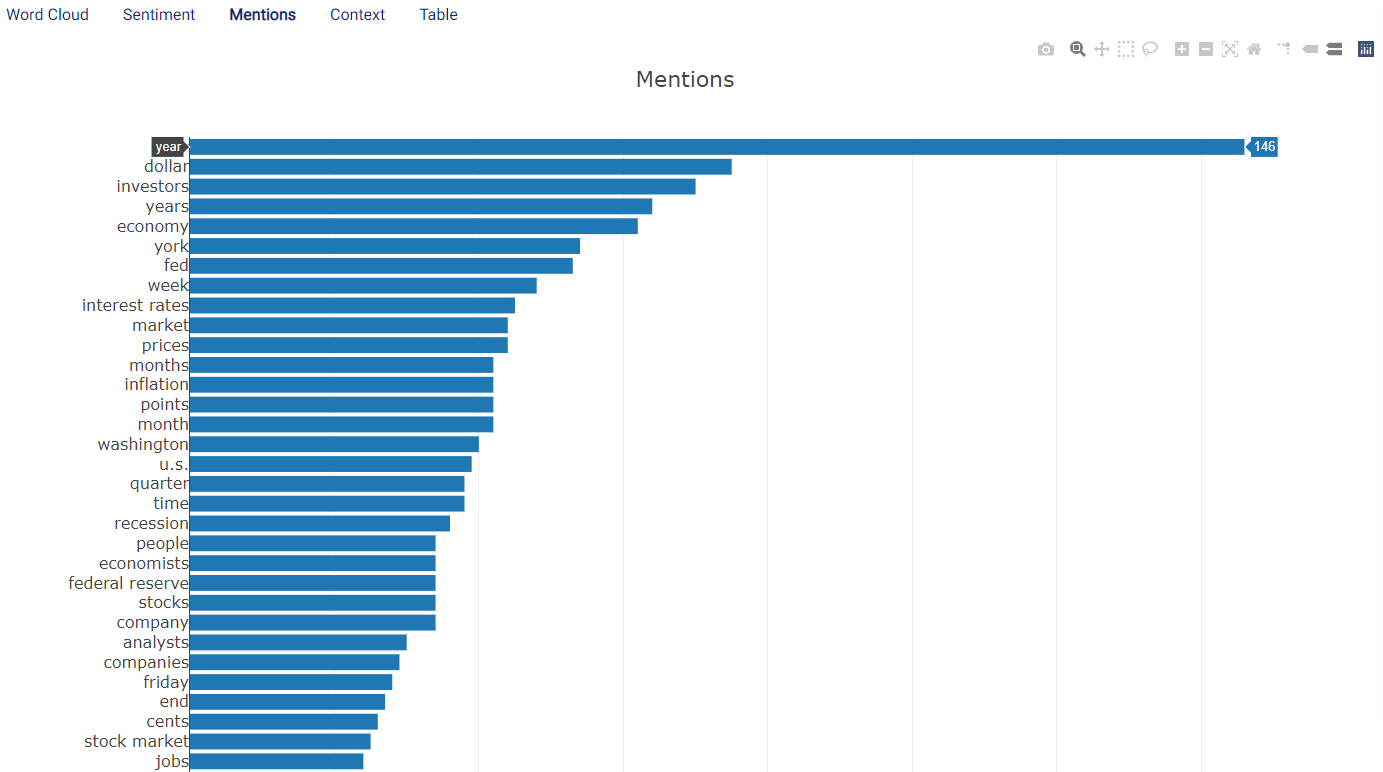
Note
The value shown in this chart may not correspond to the addition of the positive and negative occurrences shown in the Sentiment tab. This is because there may be samples classified as neutral. In the examples above, the sum of the positive and negative text samples amounts to 49 + 91 = 140, while the total number of occurrences is 146. This means that there are 146 - 140 = 6 neutral samples.
Context¶
The table in this tab highlights both keywords and the associated sentiment classification results. Actable AI tries to break down the original text into sentences and then applies keyword extraction and sentiment analysis on each sentence.
The contents of each column are as follows:
row: indicates the row number where the text is located in the original dataset.
keyword: contains the extracted keywords for the considered sentence that is shown in the sentence column.
sentence: for each row, the sentence extracted from the original text is shown.
sentiment: shows the sentiment classification result (negative, positive, or neutral).
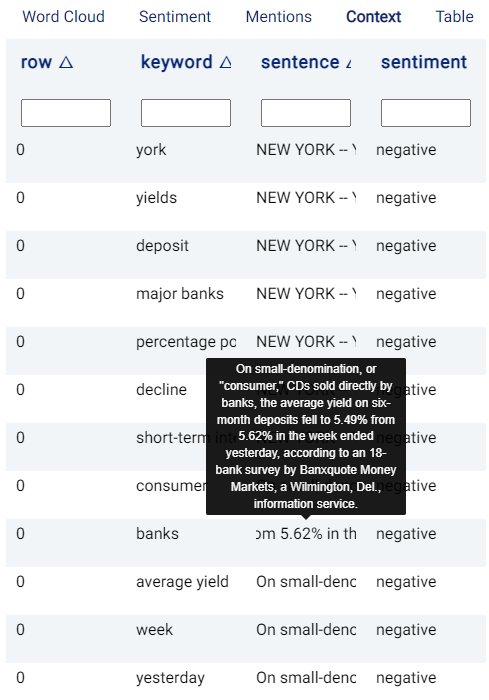
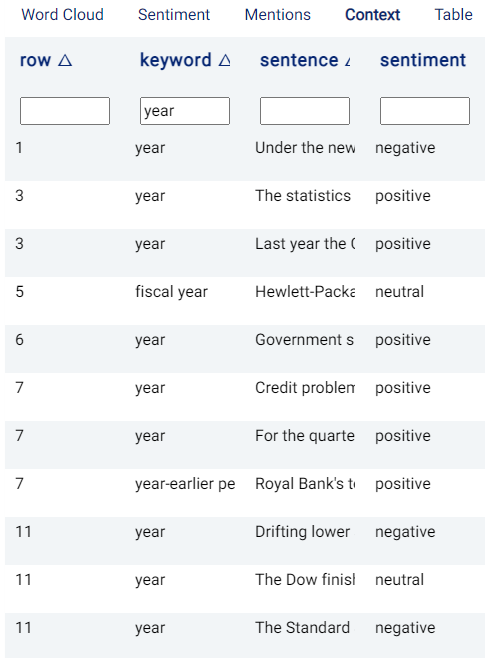
The first row in the table contains empty fields that can be used to filter the displayed rows. For example, typing in year under the keyword column returns all rows containing year as a keyword:
Table¶
The Table tab displays the first 1,000 rows in the original dataset and the corresponding values of the columns used in the analysis.
Similarly to the Context tab, the first row in the table contains an empty field that can be used to filter the displayed rows. For example, typing in year returns all rows in the dataset containing the word year.